Mosiki update: The anti-climax of software that just works
(In this blog series I attempt to develop a wiki server that tries to be respectful of computer resources, as part of a self-assigned Modest Programming Challenge, the series starts here)
A while ago I set out to make a small wiki ideal for niche communities. Easy to administer, reliable via low number of parts, respectful of computer resources both on the server side and on the client side, with little code to make it easy to pick up and maintain on one's own. It's been a while since my last update but not because I stopped the project. Actually, the wiki is up live and has been for months. So how have things turned out?
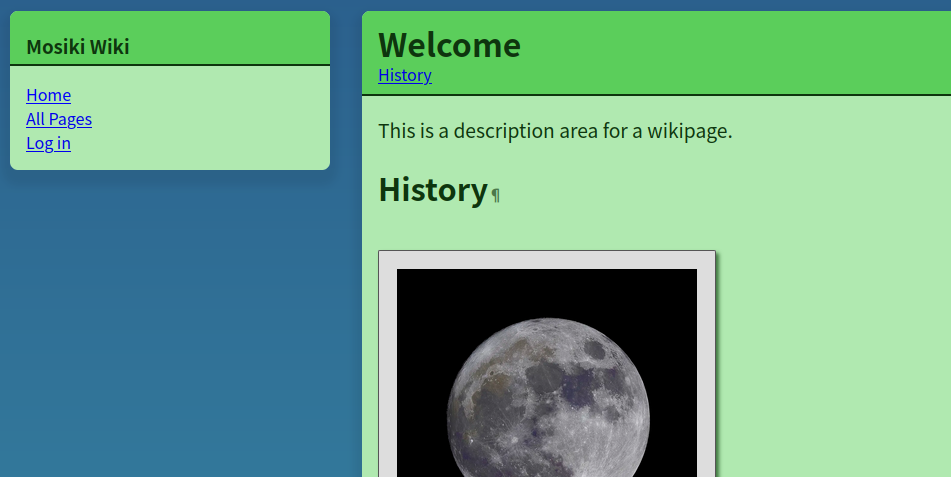 I never said I was a webdesigner btw. But you can probably tell that from my blog.
I never said I was a webdesigner btw. But you can probably tell that from my blog.
Mission success
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Python 15 612 467 1821
HTML 24 14 0 792
CSS 3 83 1 395
-------------------------------------------------------------------------------
SUM: 42 709 468 3008
-------------------------------------------------------------------------------
Mosiki has shaped up reasonably well. It has users, sign-up via an invite system, password reseting, page creation, editing, conflict management, permissions, renaming pages with URL redirects, image uploading with thumbnail generation, markdown syntax with some additions, some simple mobile responsive css, page locks, and page keys.
At idle the server uses about 90 MB of RAM, including mosiki, OS (Alpine Linux), and Nginx proxy. A reasonable example of a fairly simple page tracks in at 22KB of HTML and CSS, with obviously any attached images dwarfing that. There's no JS anywhere. It comes out at an absolutely tiny 3k lines. I feel like I can very confidentally call this some Modest™ software.
Before I finish up though, here's some more technical junk.
Yet more dependencies
Last time I went over some early choices: Flask, Gevent, Markdown via markdown-it-py, SQLite, Argon2. And all of those have ended up in. I did end up adding in a few more though.
mdit-py-plugins
This module comes from the same org as markdown-it-py and allowed me to quickly add anchor-links (as in, linking to sections of a page) and footnotes. This is perhaps one of the more dubiously low-value dependencies of the entire project, but it didn't seem fundamentally unreasonable.
I also added spoiler sections and other minor markdown tweaks myself. Additionally I found a bug in the module and submitted a fix so this silly little project has officially contributed to the ecosystem.
libvips (via the pyvips binding)
I knew I wanted image uploading in the wiki, and it seemed reasonable to want thumbnail generation to save a little on bandwidth. This is the sort of thing that when designing your software should ring bells as a potential memory hog point; if you're not careful it's easy to end up in a situation where your image processing solution loads the entire image into RAM and then processes it. Several megabyte images are fairly common, and so this could easily consume a lot of RAM with a large userbase. In practice I won't have many users so the only concern would be a denial-of-service attack, which is also very unlikely. But, this is easy enough to work around that I might as well anyway; it's good to take pride in programming resilient solutions.
Image processing is a complex enough problem that you probably should use a dependency and you should probably just pick one that removes the memory hog vector. I went with libvips. Libvips is much faster and less memory intensive than other solutions. The speed is largely due to use of SIMD, and the low memory usage is because it works on streams. This allows me to feel some confidence that Mosiki should be reasonably resilient to high file-uploading load. Honestly much higher than I ever expect it to experience.
The one thing to be careful about here is that libvips is written in an unsafe language, runs on client-controlled input and this is a server. In this situation you should always at least check that the library is fuzz-checked which will help identify security issues. Google, as much as I take issue with them as a company, does a nice public service with the oss-fuzz project and they fuzz test libvips. I checked its history of CVEss and it seems reasonable. Obviously not perfect but it seems reasonably infrequent and lots of what's there is specific limited danger issues. Hopefully distribution package maintainers stay quick on the draw there. Contrast ImageMagick which seems like should never be used in a server.
Diff-match-patch
Another obvious area of potential performance concern was text-diffing on conflict. Python provides a semi useful diff module called difflib, but it's quite slow. I considered writing my own stuff on top of it to recursively break the sequences up in order to prevent any individual diff-step getting to complex and slow, but honestly, this is the sort of thing you want to get right. And Google's diff-match-patch module seems very reasonable. It's a single file, although reasonably complex at 2k lines. It's pure python but much faster. And even supports a time limit after which it gives the diff to the current-best granularity.
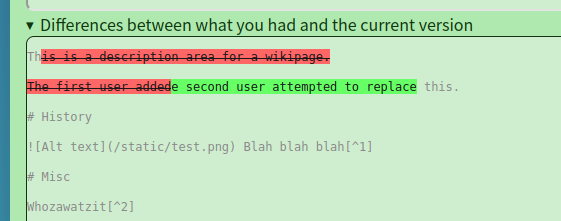 An example of a diff on Mosiki's simple conflict page.
An example of a diff on Mosiki's simple conflict page.
The module hasn't received any updates in three years. I don't consider that a bad sign. It's something with a closed scope. It simply doesn't need to do anymore, and it's something that can be verified reasonably in-depth via generative testing. As such, I have simply included the module in a "thirdparty" folder. I don't see any reason not to as I don't expect future fixes or security problems, and it's a single file. Package managers like pip are hoenstly themselves a quite dangerous point of security failures and I feel when it seems reasonable to just ship the dependency you should consider it, because package hijacking does happen. Relying on distribution package maintainers though seems to have a good track-record and so getting libvips that way for example likely increases security over shipping a fixed dependency.
And that's it. The total dependencies for this at this stage seem to be:
- Sqlite (provided by python but installing it separately for the command line programs is still helpful)
- Flask
- Markdown-it-py
- Gevent
- Argon2-cffi
- Nginx
- Mdit-py-plugins
- Pyvips/Libvips
- Diff-match-patch
- zope-interface (a dependency by something else here but I forget which one)
I feel these generally all pull their weight with maybe the exception of mdit-py-plugins.
No email
To simplify the needs of the server, no workflow in the wiki uses email. Instead users sign up via invite codes given by admins. If a user can't log in they can ask an admin to generate them a password reset link. Obviously this adds a bit of overhead but for a niche community I suspect it's reasonable. Using emails adds a whole other layer of stuff that can go wrong, and this project was specifically about making the minimal thing for my use case.
Iframes, really useful for JS-less pages?
Developing this without JS was interesting in some areas. For example, with image uploads I don't really want the entire page refreshing just because you uploaded something. The solution I went with was just that the uploads are handled in an iframe, and the iframe refreshes. And honestly it just works very well? I'm not a front-end guru though so maybe this is weird, feel free to send me scathing emails to educate me.
Accretion-only db
As a general rule, the wiki doesn't use much of UPDATE or DELETE. Instead new records are inserted and differentiated via an "updated_at" column. Current is selected via "SELECT * FROM pages ORDER BY updated_at DESC LIMIT 1", which indexes should make reasonable. This is a slightly unusual choice but I find it a safer design in general. Additionally, you usually want to keep records of what things were anyway, and this is just a very simple way to achieve that. The most notable exception is passwords, of which I only keep the most recent.
Hard limits in software are good, actually.
While programming I identified a few places where large amounts of requests could blow the server up, such as conflict resolution, image upload, password hashing (because of argon2). While this will likely never be a problem I actually have, I decided to go ahead and address them anyway. A big part of this experiment is being respectful of computer resources, and I think it takes more than just measurement; you need to proactively consider what could go wrong, and how to deal with it.
Image uploading was largely handled by libvips and wrangling file uploading to use streams rather than keeping the entire file in memory. But for password hashing and conflict resolution I decided to go ahead and use a lock to simply limit it to one request doing such work at anytime.
This may seem like an odd thing to do and yes, one at a time is definitely going to be unnecessarily limited for many real-world use-cases. Fortunately, I don't really have those use cases, but I would also argue that limiting the number of memory-intense requests is a good thing. It's tempting to write software without hard limits, but I think this is an illusion. You do have hard limits. At some point, memory runs out. If you want to feel reasonably confident that your memory usage will be low you need to pick a target, and the only way to reliably hit your target is via limits.
Things are boring when they just work.
It took me a while to get around to writing this update for perhaps the best possible reason: honestly everything went quite boringly well. The server went up (warning: nerd shit, but it's not much to see at the moment) and has stayed up for months. It requires no effort on my part, other than the occasional OS update for security patches. I should count this a total success, but man, it makes for boring blogging!
Despite the fact that I tried to write it small in order to be understandable, I'm not entirely sure that I'll ever share Mosiki; The point of this blog series was not "hey, you should use my wiki server". It was an experiment in a way of thinking, and an attempt to promote that way of thinking. I successfully made something that is useful for me and I basically don't have to worry about it, and that is honestly kind of unusual with software, but I think it shouldn't be.
I think it'd be possible to have more things that Just Worked™ if we valued different things. Conscious scope management, careful technology choices, respect for computer resources. Not everything can be as simple as my toy wiki implementation, but many could be a lot simpler than they are. And a lot more mindful of where things could go wrong.
This may well be it for this blogging series. Thank you, dear reader, for following along. I hope you found it interesting. And I hope to have more things to blog about soon that are a bit more interesting than a toy wiki.